Smart Deploys for Serverless Monorepos
Deploying to AWS through CloudFormation-backed tools like Serverless Framework, CDK, or SAM can be slow. After waiting on enough no-op deploys, I built a CI flow for serverless monorepos that only runs the work a change requires.
The concept is elegantly simple:
Every push does the correct minimal amount of work. Nothing more.[1]
I call this the smart deploy flow.
A push comes in. The pipeline detects what changed, figures out whether this is a fast code deploy or a full infrastructure deploy, derives a dependency graph from the IaC, and then deploys the affected services in parallel waves.
No manual coordination. No giant "deploy everything because I am scared" button. No brittle hand-maintained dependency list that rots after the third refactor.
The graph is already hiding in the repo. Might as well use it.
The serverless monorepo problem
Serverless monorepos usually fall into one of two bad deploy modes:
- Redeploy everything. Safe-ish, but slow, noisy, and hard to debug when one unrelated stack fails.
- Deploy only the changed folder. Fast, but often wrong.
Real services are not isolated folders. They depend on shared packages, generated clients, environment contracts, API Gateway routes, event schemas, CloudFormation outputs, IAM roles, queues, topics, buckets, tables, layers, domains, and whatever else the system grew over time.
Changing packages/auth might require redeploying five services.
Changing a CloudFormation output might require redeploying every consumer of that output.
Changing a Lambda handler implementation might only need a fast code update.
Changing timeout, memory, event sources, table schemas, API routes, or IAM policies needs a real infrastructure deploy.
Those are different situations. The pipeline needs to tell them apart.
Use the graph, Luke
Do not encode deploy order by hand. Derive it from the same source of truth that creates the system.
A serverless repo already has three graphs worth reading:
- The git change graph: what files changed in this push.
- The code/package graph: which packages and services import each other.
- The infrastructure graph: which deployable units produce and consume resources.
Once you have those graphs, deployment planning stops being a pile of YAML conditionals.
flowchart LR
Push[Git push] --> Diff[Detect changed files]
Diff --> Source[Source and package graph]
Diff --> IaC[IaC graph]
Source --> Affected[Affected deployable units]
IaC --> Affected
Affected --> Strategy{Deploy strategy}
Strategy --> Fast[Fast code deploy]
Strategy --> Full[Full infrastructure deploy]
Fast --> Plan[Topological plan]
Full --> Plan
Plan --> Wave1[Wave 1]
Plan --> Wave2[Wave 2]
Plan --> Wave3[Wave 3]
Wave1 --> Wave2
Wave2 --> Wave3Parallelism is the easy part. The hard part is knowing which things can safely run at the same time.
What counts as a deployable unit?
Treat every deploy target, and every shared input that can affect one, as a graph node. That includes Serverless Framework services, CDK/SAM/CloudFormation stacks, Lambda packages, frontends, workers, and shared packages that do not deploy directly.
The planner only needs a normalized view:
{
"id": "api-service",
"path": "services/api",
"kind": "serverless",
"package": "@acme/api-service",
"produces": [
"ApiGatewayRestApiId",
"UsersTableName"
],
"consumes": [
"AuthUserPoolId",
"EventsTopicArn"
],
"dependsOn": [
"auth-service",
"event-bus"
]
}To build that DAG, you need to know each service's inputs and outputs. I use Configorama for this. It can parse YAML, JSON, TOML, HCL/Terraform, JavaScript, TypeScript, and other config formats, then analyze variables and file dependencies without fully resolving everything.
That makes the boring part much easier: read the service config, pull out what it consumes and produces, and turn that into graph edges instead of maintaining a second dependency map by hand.
Each plugin can do the framework-specific parsing. The planner just needs nodes and edges.
Change detection is not enough
Most "smart CI" starts and stops with paths:
services/api/** changed -> deploy api
services/worker/** changed -> deploy workerPath matching helps, but it only tells you what changed directly.
For example:
packages/shared-auth/session.js changed
-> api-service imports @acme/shared-auth
-> dashboard-service imports @acme/shared-auth
-> notification-service does notOnly the services that consume the changed package should be candidates for deploy.
Now add infrastructure:
services/auth/serverless.yml changed
-> AuthUserPoolId output changed
-> api-service consumes AuthUserPoolId
-> dashboard-service consumes AuthUserPoolIdThe affected set is everything reachable from the change across code and infrastructure dependencies:
function collectAffectedServices(changedNodes, graph) {
const affected = new Set(changedNodes)
const queue = [...changedNodes]
while (queue.length) {
const current = queue.shift()
const dependents = graph.dependentsOf(current)
for (const dependent of dependents) {
if (affected.has(dependent)) continue
affected.add(dependent)
queue.push(dependent)
}
}
return [...affected]
}Start with direct changes, then walk outward to anything that depends on them.
Fast code deploy or full infrastructure deploy?
Not every change needs the same machinery.
If only Lambda code changed, the fastest path might be a package upload or function code update. If infrastructure changed, the control plane needs the full IaC deployment path.
Full CloudFormation deploys are slower and have more failure modes. Use them when the resource graph changed, not because a handler had a typo fix.
A simple classifier is enough to start:
const infrastructureFiles = [
/serverless\.ya?ml$/,
/template\.ya?ml$/,
/cdk\.json$/,
/infra\//,
/stacks\//,
]
const configFiles = [
/package\.json$/,
/pnpm-lock\.yaml$/,
/yarn\.lock$/,
/package-lock\.json$/,
]
function classifyDeploy(files) {
if (files.some((file) => infrastructureFiles.some((rule) => rule.test(file)))) {
return 'full-infrastructure-deploy'
}
if (files.some((file) => configFiles.some((rule) => rule.test(file)))) {
return 'validate-and-package'
}
return 'fast-code-deploy'
}In a production version, this gets more nuanced:
- Handler code changed: fast deploy.
- Dependencies changed: package, validate, maybe deploy affected services.
- Environment variables changed: depends on where env var is consumed, could be function or full stack deploy.
- IAM changed: full deploy.
- CloudFormation outputs changed: full deploy producers and affected consumers.
- Shared package changed: redeploy downstream consumers.
- Unknown change: fallback to full slower safer deploy.
This can get tricky but once you smooth over some rough edges, your deploy times will fly. This is critical for fast agent feedback debug loops.
Spend the slow path only when it buys correctness.
Derive deployment waves from IaC
Once you know the affected deployable units, topologically sort them into waves. If api-service consumes outputs from auth-service, auth-service goes first. If worker-service and frontend-service do not depend on each other, they can share a wave.
[
{
"wave": 1,
"services": ["auth-service", "event-bus", "database"]
},
{
"wave": 2,
"services": ["api-service", "worker-service"]
},
{
"wave": 3,
"services": ["dashboard-service", "notification-service"]
}
]Everything inside a wave runs in parallel. The next wave waits.
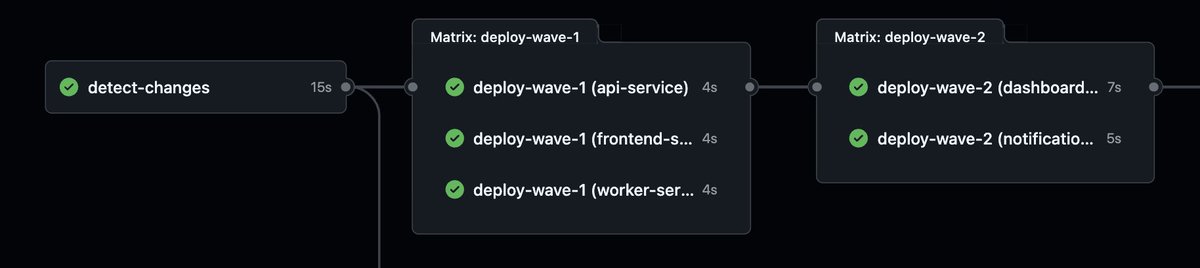
GitHub Actions is a decent fit for this because dynamic matrices map cleanly to waves:
jobs:
detect-changes:
runs-on: ubuntu-latest
outputs:
wave_1: ${{ steps.plan.outputs.wave_1 }}
wave_2: ${{ steps.plan.outputs.wave_2 }}
steps:
- uses: actions/checkout@v4
- id: plan
run: node scripts/plan-deploy.js
deploy-wave-1:
needs: detect-changes
if: ${{ needs.detect-changes.outputs.wave_1 != '[]' }}
strategy:
fail-fast: false
matrix:
service: ${{ fromJson(needs.detect-changes.outputs.wave_1) }}
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- run: pnpm deploy --filter ${{ matrix.service }}
deploy-wave-2:
needs: deploy-wave-1
if: ${{ needs.detect-changes.outputs.wave_2 != '[]' }}
strategy:
fail-fast: false
matrix:
service: ${{ fromJson(needs.detect-changes.outputs.wave_2) }}
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- run: pnpm deploy --filter ${{ matrix.service }}With fixed workflow YAML, predefine a maximum number of wave jobs and emit empty matrices for unused waves.
Alternatively, you can orchestrate with something like AWS Step functions or another orchestration layer.
Failure modes
This can go wrong in one boring way: the planner gets overconfident. If it misses a dependency, it can skip work that should have run. Worse than slow.
When the graph cannot prove a narrower deploy is safe, widen the affected set.
Practical guardrails:
- If the IaC parser fails, run the full deploy path.
- If a package dependency cannot be resolved, include all likely consumers.
- If a lockfile changes, validate and package affected services.
- If a shared config file changes, include every service that reads it.
- If graph cycles appear, fail early with a useful error.
- If a deployable unit has unknown consumers, deploy it before dependents or force manual review.
Content fingerprints help. After the planner chooses candidates, each deployable unit can hash the files that affect its artifact.[2]
service source files
+ imported workspace packages
+ lockfile slice
+ IaC template
+ deployment config
+ runtime version
= deploy fingerprintIf the fingerprint matches the last successful deployment, skip it.
The graph decides what might be affected. The fingerprint catches the cases where the deployable artifact never changed.
Why I want this in CI
Slow pipelines change team behavior.
When deploys take too long, people batch changes. Bigger batches make failures harder to isolate. Hard-to-isolate failures make people trust CI less. Then they add bypasses, retries, manual steps, and "just this once" exceptions.
Fast, correct deploys create the opposite pressure: small changes stay small, failures point closer to the source, and deploy minutes go down. The system is easier to reason about because the plan is visible:
Changed:
packages/auth/session.js
services/auth/serverless.yml
Affected:
auth-service full-infrastructure-deploy
api-service validate-and-package
dashboard-service validate-and-package
Plan:
wave 1: auth-service
wave 2: api-service, dashboard-serviceThat output is the real product. The CI graph only executes it.
Make it zero config
For service owners, this should be zero config.[3] Define the service once, the same way it is already defined for deployment. The CI system reads that definition instead of forcing a second hand-written dependency list:
api-service:
deployAfter:
- auth-service
- databaseIf the service consumes AuthUserPoolId, imports @acme/shared-auth, or emits an API URL consumed by the dashboard, the graph should know.
The repo already contains the truth. Make the deployment system read it.
Plugins vary across Serverless Framework, CDK, SAM, CloudFormation, Terraform/OpenTofu, frontends, workers, and internal platforms. The graph loop stays the same:
- Detect the change.
- Expand to affected dependents.
- Classify the safest deployment strategy.
- Topologically sort the affected graph.
- Run each wave in parallel.
- Skip artifacts whose fingerprints did not change.
That is smart deploy.