The rise of embarrassingly parallel serverless compute
Let's begin by suspending disbelief for a moment and imagine this scenario:
Imagine an application that would normally take 1 hour to run on a single machine...
What if instead you could spin up 3600 lambdas that each run for one second to return near instantaneous results
Is this science fiction? Perhaps a developer's fever dream? Or possibly fake news?
None of the above. This is a reality today. This quote is an excerpt from this excellent Stanford seminar by Keith Winstein where he details the research being put into the future of compute.
We've entered an era of the serverless supercomputer.
A world where embarrassingly parallel compute is not only possible but accessible to everyone.
Monolithic limitations
Even with gigantic instances, there are physical hardware limitations when compute is isolated to an individual machine.
Given these constraints, it makes sense to shard the machines, spin up new instances, and batch up the work for parallel processing. Share the burden & get multiple machines to pitch in. I love it!
This is all well and good, but there are numerous operational complexities with this approach. Requiring data scientists to be masters in the arts of DevOps is a tall order.
Additionally, keeping these giant instances at the ready is cost-prohibitive. Thus, when jobs need to be done, new boxes must be spun up. This a considerable amount of time compared to alternative approaches.
Finally, there are still constraints under this model due to the underlying architecture & shared resources of their "single machine" nature.
There is "no moore free lunch" as processing power seems to be slowing & when Moore's Law no longer delivers. Come on quantum computing!
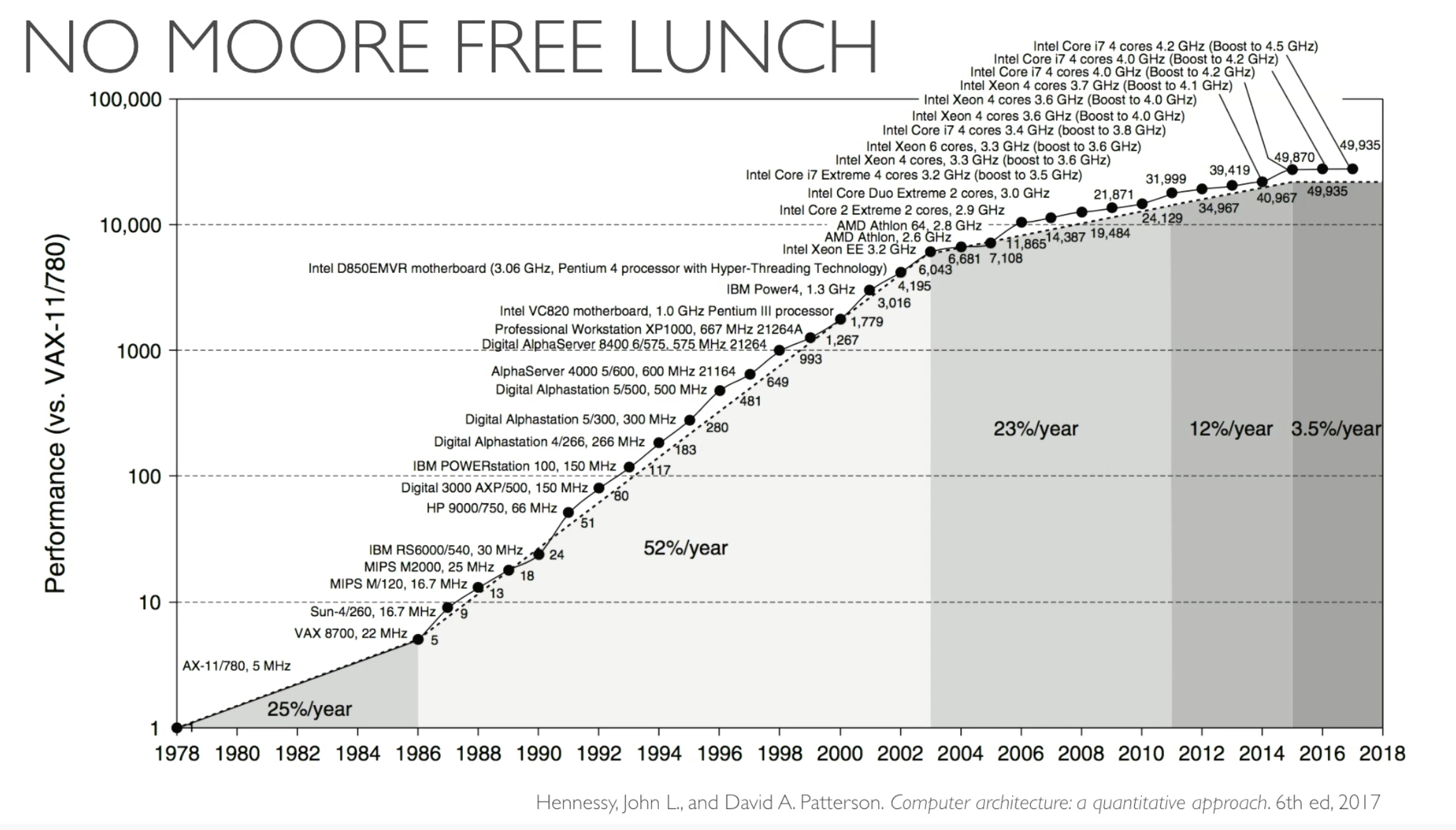
Note: If you are comfortable with Kubernetes and scaling out clusters for big data jobs & the parallel workloads described below, godspeed! The approach described below in "serverless compute" section would work in in managed servers with the typical manage it yourself caveats.
For the adventurous, curious about how this looks in a serverless world, continue reading.
Enter Serverless Compute
What does this same view look like in a serverless model when a "FAAS" is leveraged.
Like before, jobs are batched up, and thousands of workers are spun up to handle the task. The difference here, however, is how those workers are spun up and the speed at which this happens.
"gg is more than 45× faster than Google Kubernetes Engine at startup, and 13× faster than Spark-on-Lambda" (see below on GG framework)
Below is a simplified view of how FAAS providers spin up function instances in parallel to respond to requests.
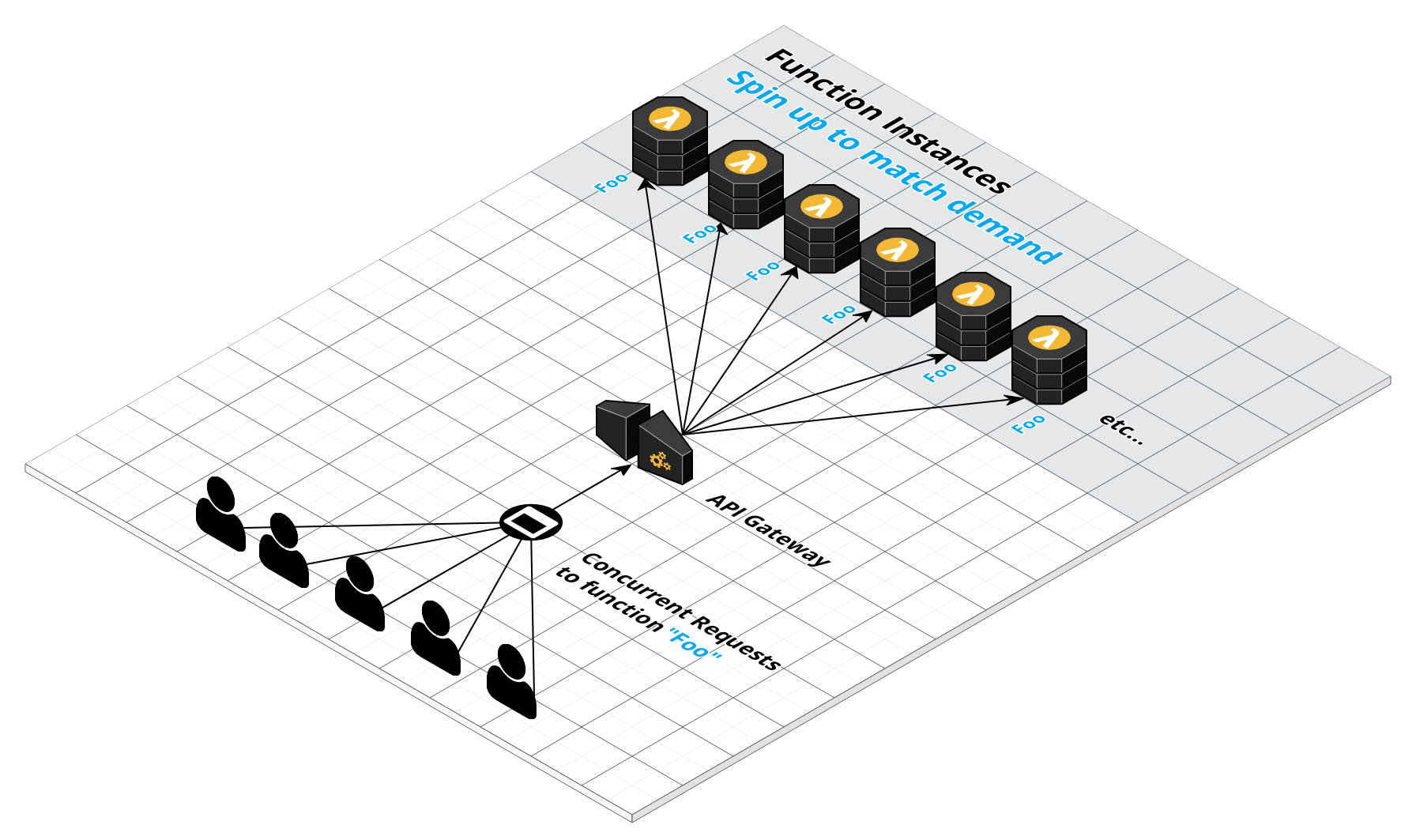
Using this on-demand scale from serverless FAAS providers, jobs can be spun up in as many workers as required.
This would be equivalent to summoning thousands of threads, running in parallel with an instant startup.
Much like AWS s3 is an "unlimited file storage service", AWS Lambda is effectively leveraged here as "unlimited on-demand compute threads".
Note: The soft limit on AWS accounts is 1000 concurrent function invocations to avoid runaway function calls, but this can be lifted by contacting AWS based on your needs.
Use cases
What kinds of things can we do with embarrassingly parallel serverless compute?
I'm glad you asked! Turns out quite a bit:
- Software compilation
- Software testing
- Image & Video encoding, analysis, compression
- Machine Learning
- Data visualization
- Genomics
- Monte Carlo simulations
- Fast Search
- CI/CD
- ... dare I say anything?*
Any processes that can be chunked up and processed in pieces in a distributed fashion is suitable for this massive parallel runtime.
So why isn't everything fast, amazing, and running this way already?
One of the challenging parts about this today is that most software is designed to run on single machines, and parallelization may be limited to the number of machine cores or threads available locally.
Because this architecture & "serverless compute" is so new (cough cough 2014), most software is not designed to leverage this approach. I see this changing in the future as more become aware of this approach.
Let's explore some real-world examples of massive parallelization working.
Real-world examples
Before we continue, I highly recommend strapping in and watching the video below. It goes in-depth into several use cases & demonstrations on the efficacy of this approach.
Now onto some additional examples!
Projects
- Excamera - video encoding, a functional video codec for fine-grained parallelism
- Lepton - JPEG recompression, a functional JPEG codec for boundary oblivious sharding
- Salsify - video conferencing codec to find optimal encoding rates
- GG - thunk abstraction to infer a lambda expression & evaluate in serverless compute
- CC-lambda
- Pywren - Run your existing python code at massive scale via AWS Lambda
- serverless-artillery - performance testing at scale
- lambci - A continuous integration system built on AWS Lambda
- Parallel image processing
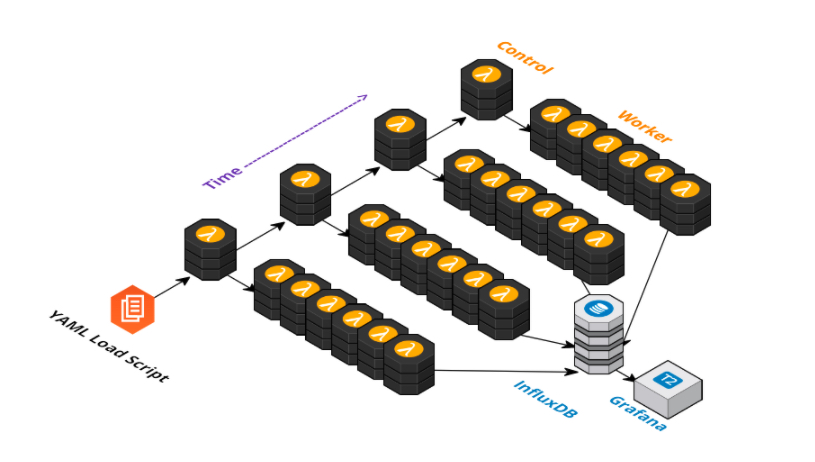
GG Framework
gg framework is an open-source framework that helps developers execute applications using thousands of parallel threads on a cloud function service to achieve near-interactive completion times.
GG breaks down larger tasks into an intermediate representation, a collection of "thunks", that is cloud-agnostic. That is then sent over the wire to a given cloud service.
"The goal is to provide results to an interactive user—much faster than can be accomplished on the user's own computer or by booting a cold cluster, and cheaper than maintaining a warm cluster for occasional tasks."
"PyWren exposes a Python API and uses AWS Lambda functions for linear algebra and machine learning. Serverless MapReduce and Spark-on-Lambda demonstrate a similar approach."
"gg is more than 45× faster than Google Kubernetes Engine at startup, and 13× faster than Spark-on-Lambda"
LambCI
Run CI in parallel and go FAST ⚡️
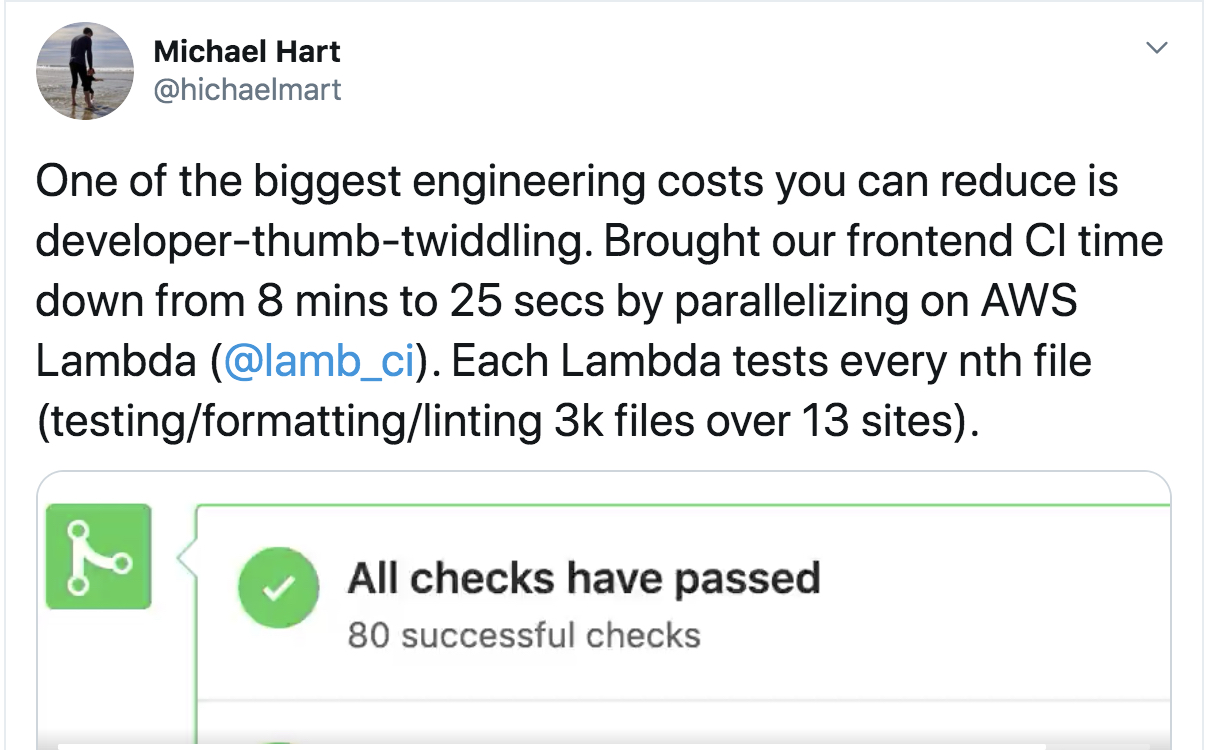
From hichaelmart
Nordstorm artillery
Stress-test your systems at any scale. 🚀
Hammer services to verify their production readiness with a fleet of functions.
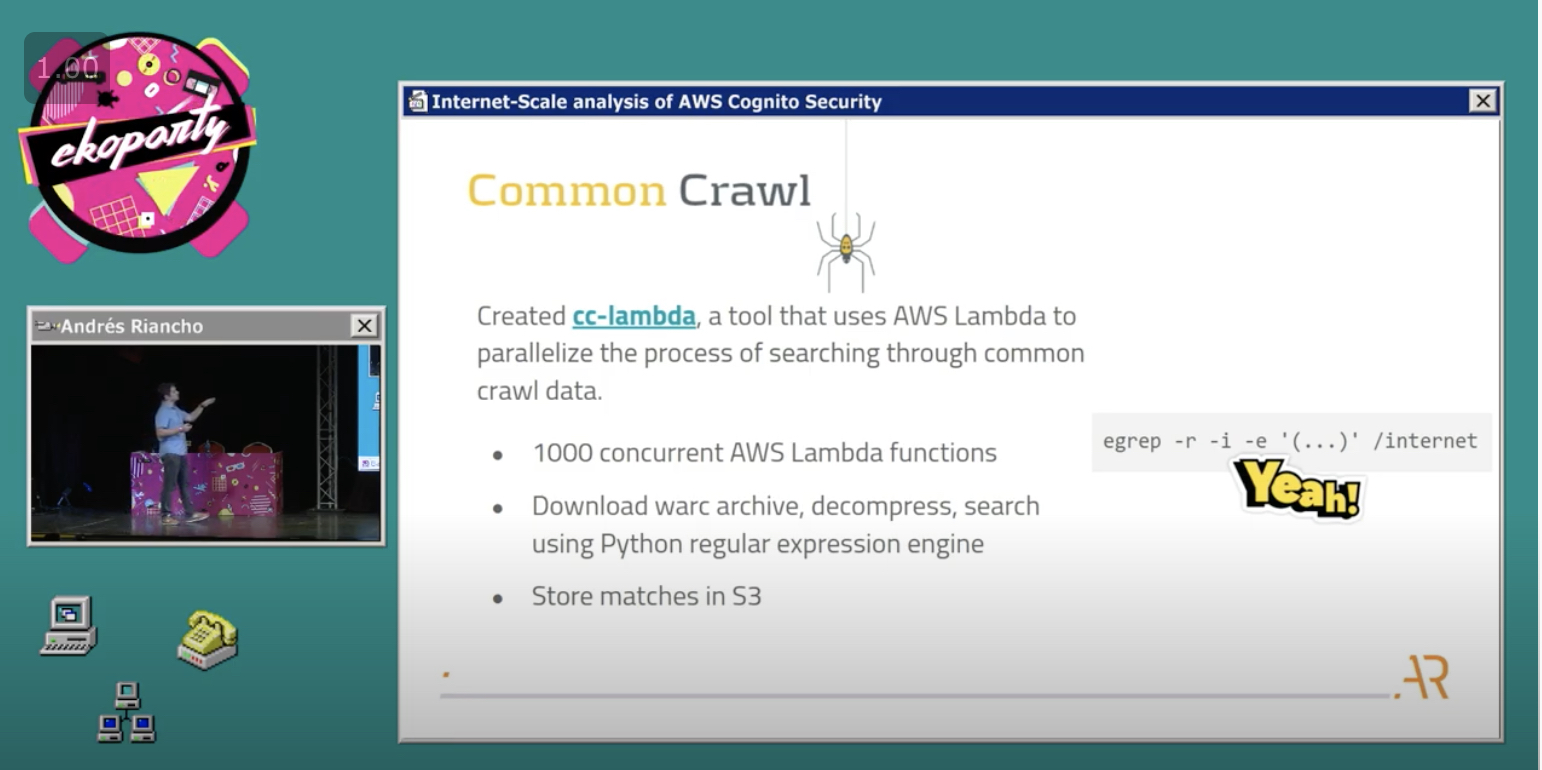
CC lambda
Process 3.5 billion webpages or 198TB of uncompressed data in ~3 hours.
Basically grep for the internet.
Additional examples
Speeding up EMR jobs
Using lambda to speed up Elastic map reduce jobs.

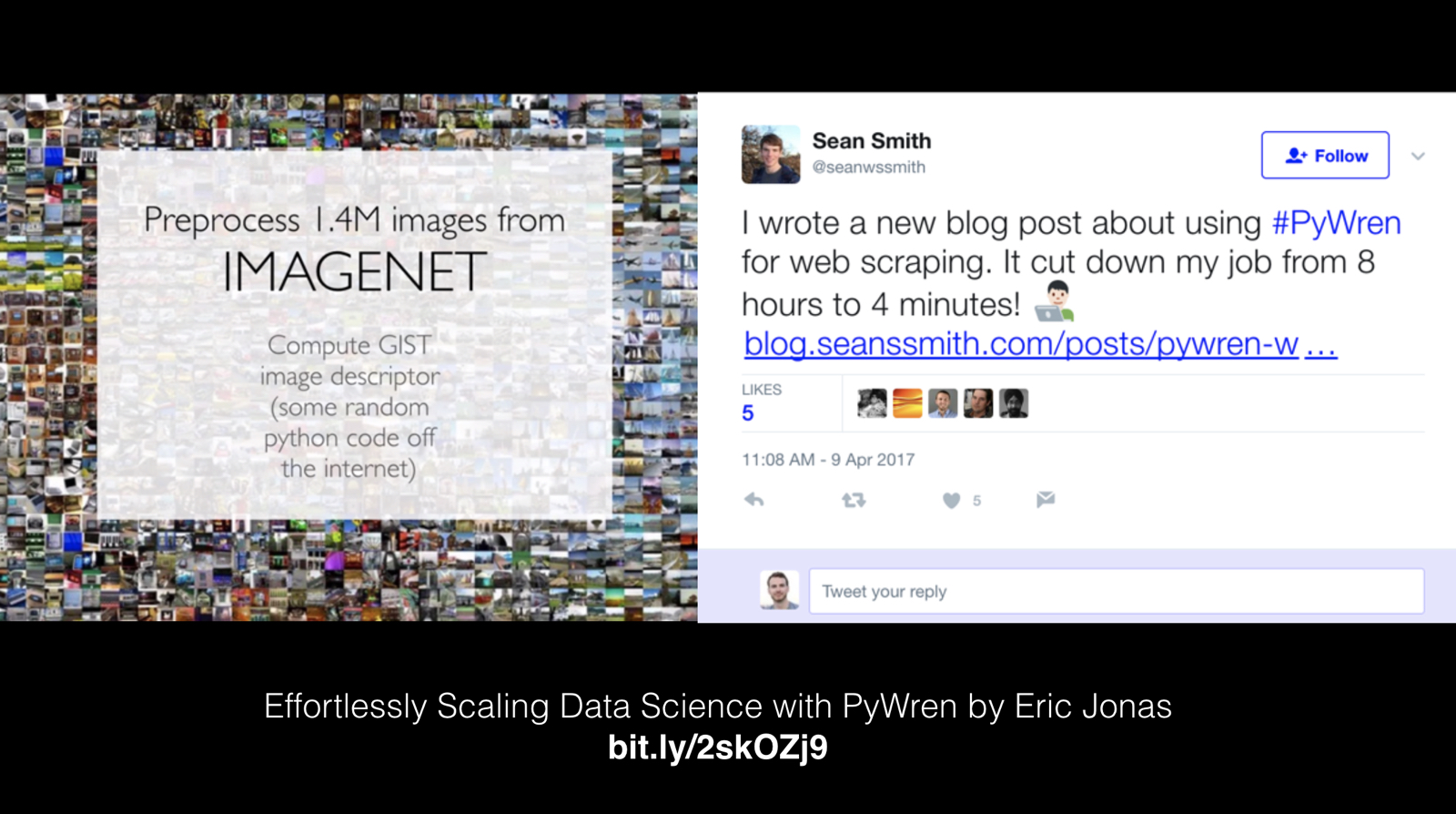
Scraping at scale
Using Pywren to handle massive scraping jobs.
Machine learning
Using lambda to do massively parallel hyperparameter search with fasttext.
AWS Lambda blows my mind every time I flex it. Currently executing 2000 parallel 15min functions doing a hyperparameter search with fasttext. 🤯 Would take me frikken hours to do this any other way.
Others...
There are many many projects out there like this.
If you have seen others. Please let me know in the comments below!
Resources & links
- PyWren: Pushing Microservices to Teraflops, Eric Jonas
- Outsourcing Everyday Jobs to Thousands of Transient Functional Containers
- Massively Parallel Hyperparameter Optimization on AWS Lambda
- From Laptop to Lambda: Outsourcing Everyday Jobs to Thousands of Transient Functional Containers
- Serverless State - Tim Wagner's keynote from SLS conf 2019
- Tiny functions for codecs, compilation, and (maybe) soon everything - Stanford Seminar
- GG framework demo
- Occupy the Cloud: Distributed Computing for the 99%
- A Berkeley View on Serverless Computing
- Parrellel computing history
- Jeremy Daly & Michael Hart discuss massively-parallel-hyperparameter-optimization on Lambda
Wrapping up
I hope you see as I do; there is much promise in leveraging serverless compute as the supercomputer of the future.
Imagine a world where nearly everything becomes MUCH faster.
Massive data science jobs runtimes can be reduced for scientists to simulate models faster! Search can improve. Software compilation & dev cycles can be dramatically reduced... You get the point.
Think of the possibilities!
Some challenges lie ahead:
- Making current tools operate in a genuinely parallel distributed fashion
- Improving tooling & DX to make these methods approachable by all (not just Ops folks)
- Educating folks on serverless methodologies & what is possible today with managed cloud services
I will leave you with a question:
What will you do with your serverless supercomputer?